Random Forests
POLS 3220: How to Predict the Future
Ensemble Models

The Rotten Tomatoes Random Forest

Predictor variables included: release date, genre, content rating, director, actors, distributor, runtime, and audience count.
I built 500 classification trees, each trained on a random subset of the data.
I asked each tree to predict the probability that a movie would fall into one of the three rating categories (Certified Fresh, Fresh, or Rotten).
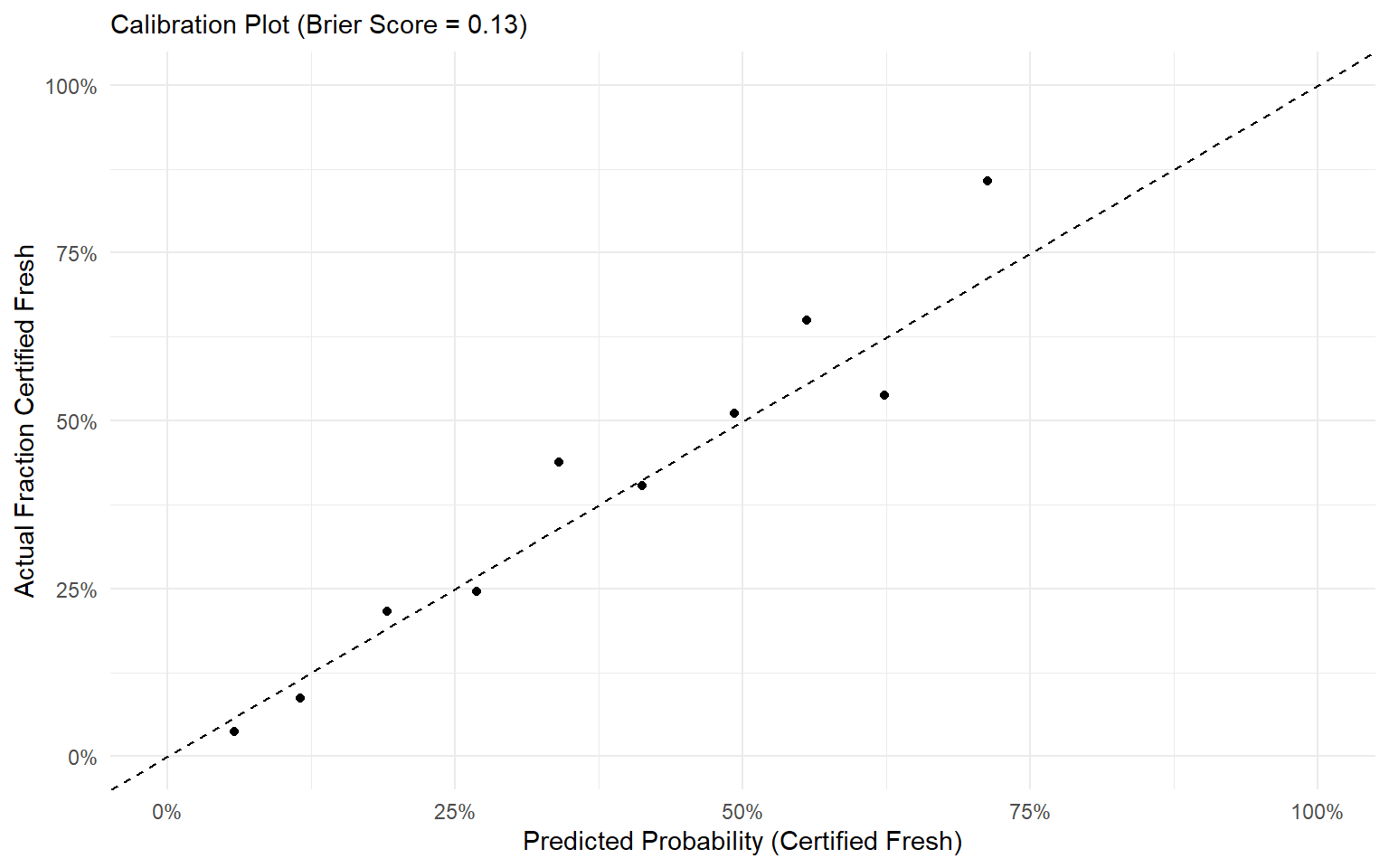
Following best practices, I hid 20% of the data from the model as a test set, to assess how well it performs at out-of-sample prediction.
Out-of-Sample Prediction
Out-of-Sample Prediction
Out-of-Sample Prediction
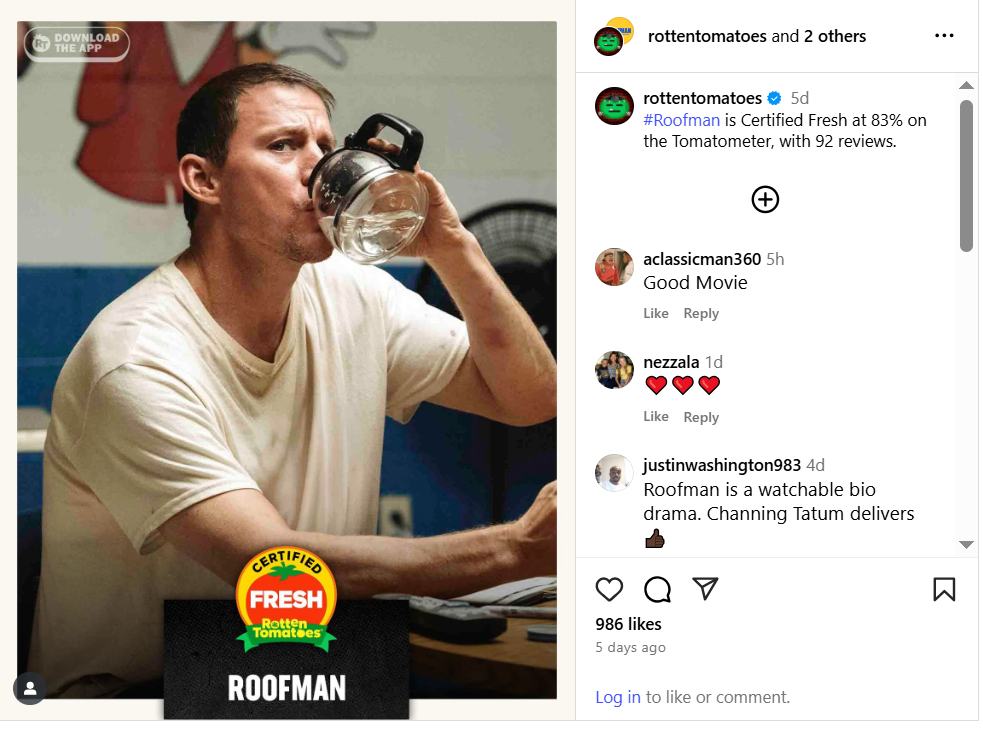
But What About Roofman???

But What About Roofman???
According to the Rotten Tomatoes Random Forest model, Roofman had a 69% chance of earning a Certified Fresh rating, and a 14% chance of being just regular Fresh.