| Rating | Total | % |
|---|---|---|
 |
3,259 | 18.4 |
 |
6,844 | 38.7 |
 |
7,565 | 42.8 |
Tree Models
POLS 3220: How to Predict the Future
Motivating Problem

Can we predict a movie’s Rotten Tomatoes rating?
Predictor Variables: Content Rating, Genre, Release Date, Distributor, Runtime, Number of Audience Reviews
Classification Trees
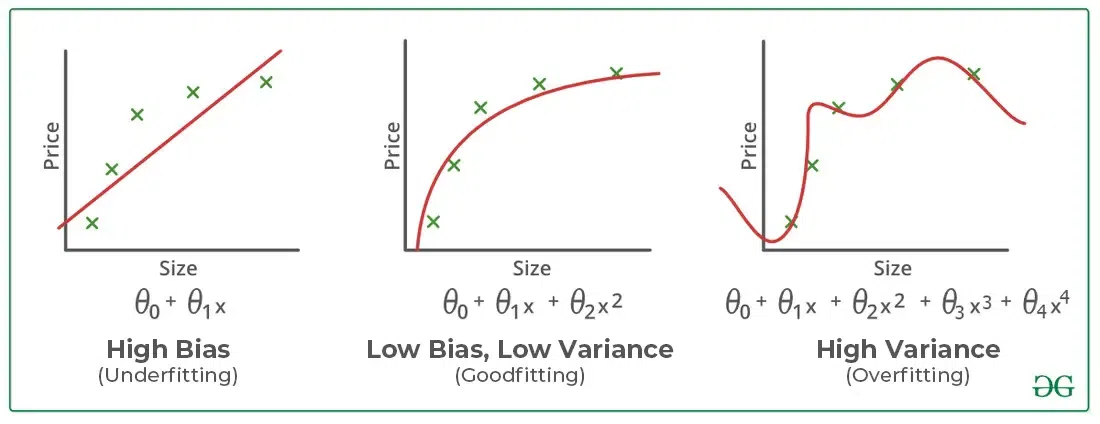
With each partition, your prediction becomes less biased.
Criterion, Searchlight, or A24
| Rating | Total | % |
|---|---|---|
|
118 | 37.2 |
|
135 | 42.6 |
|
64 | 20.2 |
Other Distributors
| Rating | Total | % |
|---|---|---|
|
3,105 | 18.4 |
|
6,396 | 37.9 |
|
7,357 | 43.6 |
Classification Trees
With each partition, your prediction becomes less biased.
Audience Count < 10,000
| Rating | Total | % |
|---|---|---|
|
1,293 | 12.0 |
|
5,052 | 46.9 |
|
4,427 | 41.1 |
Audience Count >= 10,000
| Rating | Total | % |
|---|---|---|
|
1,811 | 30.8 |
|
1,193 | 20.3 |
|
2,870 | 48.9 |
Information Theory: Review
| Rating | Total | p |
|---|---|---|
|
3,259 | 0.184 |
|
6,844 | 0.387 |
|
7,565 | 0.428 |
Information Theory: Review
| Rating | Total | p | -log(p) |
|---|---|---|---|
|
3,259 | 0.184 | 2.44 |
|
6,844 | 0.387 | 1.37 |
|
7,565 | 0.428 | 1.22 |
\(\text{Entropy} = -\sum p\times log(p)=\) 1.5 bits.
Information Gain
Audience Count < 9,000
| Rating | Total | % |
|---|---|---|
|
1,328 | 12.1 |
|
5,161 | 47.1 |
|
4,462 | 40.7 |
Entropy: 1.41 bits
Audience Count >= 9,000
| Rating | Total | % |
|---|---|---|
|
1,894 | 31.5 |
|
1,219 | 20.3 |
|
2,899 | 48.2 |
Entropy: 1.5 bits
Classification Trees
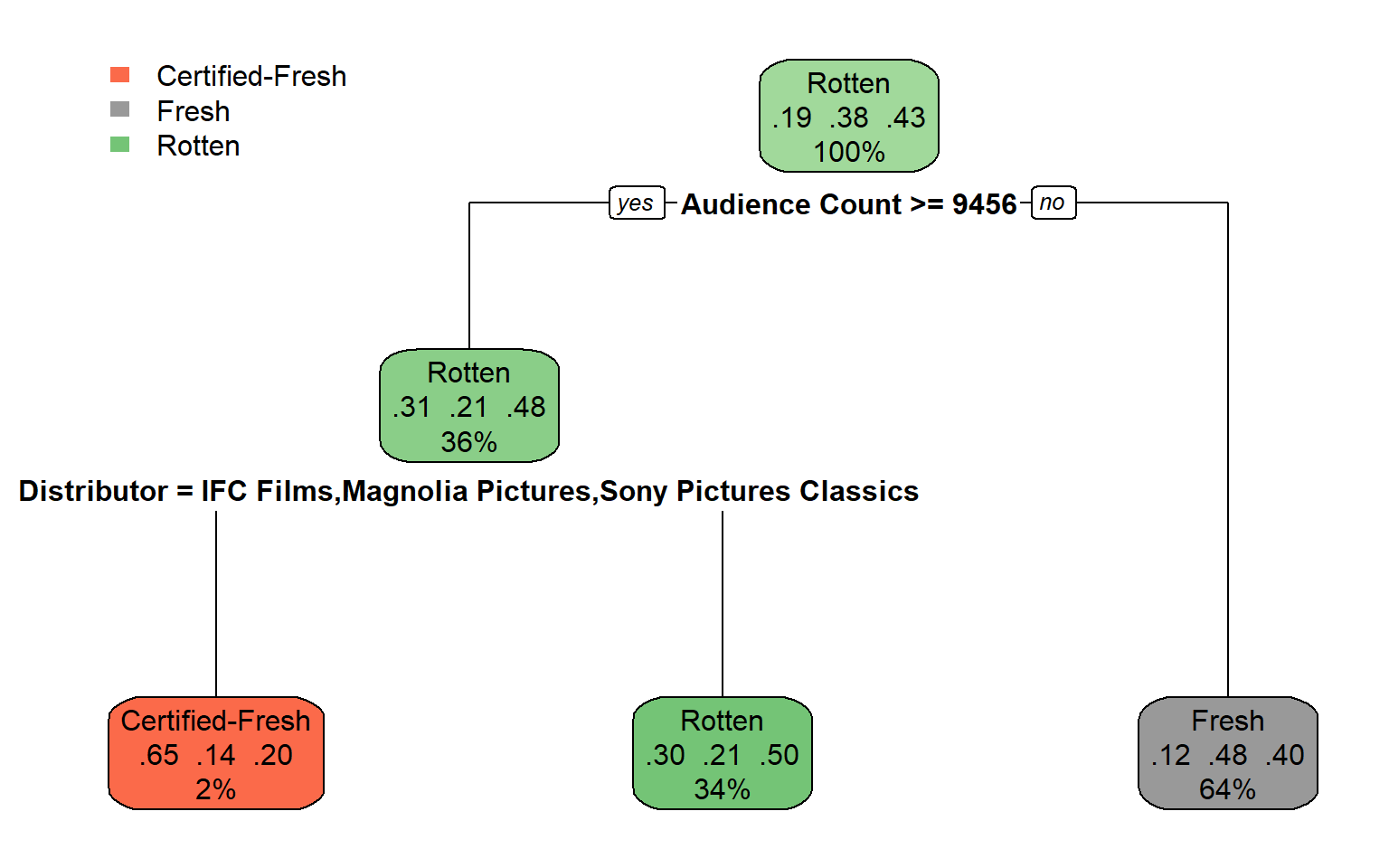
How Complex Should The Tree Get?
Bias-Variance Tradeoff
- In machine learning, this tradeoff is called overfitting vs. underfitting.