Intuition
The workhorse model for assigning topics to texts is the Latent Dirichlet Allocation (LDA), which is a sort of mix between the bag of words model and clustering. I like to think of it as a “bag of bags of words”. Imagine that, rather than drawing from a single bag of words, authors first draw a topic, which has its own special bag of words. This approach is particularly useful when we think that a document may be about more than one topic, and we don’t want to impose just one classification for each text like we do with k-means.
To demonstrate the workflow in R, let’s take the set of Senator Lautenberg’s press releases from the clustering tutorial and fit an LDA using the topicmodels package.
Step 1: Load the Documents and Tidy Up
load('data/press-releases/lautenberg-press-releases.RData')
tidy_press_releases <- df |>
# remove a common preamble to each press release
mutate(text = str_replace_all(text,
pattern = ' Senator Frank R Lautenberg Press Release of Senator Lautenberg ',
replacement = '')) |>
# tokenize to the word level
unnest_tokens(input = 'text',
output = 'word') |>
# remove stop words
anti_join(get_stopwords()) |>
# remove numerals
filter(str_detect(word, '[0-9]', negate = TRUE)) |>
# generate word stems
mutate(word_stem = wordStem(word)) |>
# count up the word stems in each document
count(id, word_stem) |>
# remove empty strings
filter(word_stem != '')
head(tidy_press_releases)# A tibble: 6 × 3
id word_stem n
<int> <chr> <int>
1 1 account 2
2 1 also 2
3 1 america 2
4 1 american 1
5 1 answer 1
6 1 apologi 1Step 2: Convert to a Document-Term Matrix
Note LDA requires a matrix of counts, just like the multinomial bag of words model.
lautenberg_dtm <- cast_dtm(data = tidy_press_releases,
document = 'id',
term = 'word_stem',
value = 'n')
lautenberg_dtm<<DocumentTermMatrix (documents: 558, terms: 7073)>>
Non-/sparse entries: 81504/3865230
Sparsity : 98%
Maximal term length: 33
Weighting : term frequency (tf)Step 3: Fit the Model
Fitting an LDA is just one line of code. It’s the interpretation, evaluation, and refinement that’s the tricky part.
Step 4: Interpret the Topic-Level Probability Vectors
Let’s look at the most common terms by topic.
# use the tidy() function from tidytext to extract the beta vector
lautenberg_topics <- tidy(lautenberg_lda, matrix = 'beta')
lautenberg_topics |>
group_by(topic) |>
slice_max(beta, n=10) |>
arrange(topic, -beta)# A tibble: 300 × 3
# Groups: topic [30]
topic term beta
<int> <chr> <dbl>
1 1 program 0.0203
2 1 grant 0.0194
3 1 lautenberg 0.0144
4 1 safeti 0.0143
5 1 d 0.0136
6 1 educ 0.0127
7 1 school 0.0117
8 1 nj 0.0115
9 1 fund 0.0112
10 1 provid 0.0110
# ℹ 290 more rowsSurprise, surprise. The most common term in each topic is often “Lautenberg”. Instead of looking at the terms with the highest probability in each bag, let’s look at the terms that are the most over-represented, compared to their probability in the average topic.
lautenberg_topics |>
# get each word's average beta across topics
group_by(term) |>
mutate(average_beta = mean(beta)) |>
ungroup() |>
# compare beta in that topic with the average beta
mutate(delta = beta - average_beta) |>
# get the words with the largest difference in each topic
group_by(topic) |>
slice_max(delta, n = 10) |>
# plot it
ggplot(mapping = aes(x=delta, y=reorder(term, delta))) +
geom_col() +
theme_minimal() +
facet_wrap(~topic, scales = 'free') +
labs(x = 'Term Probability Compared to Average',
y = 'Term')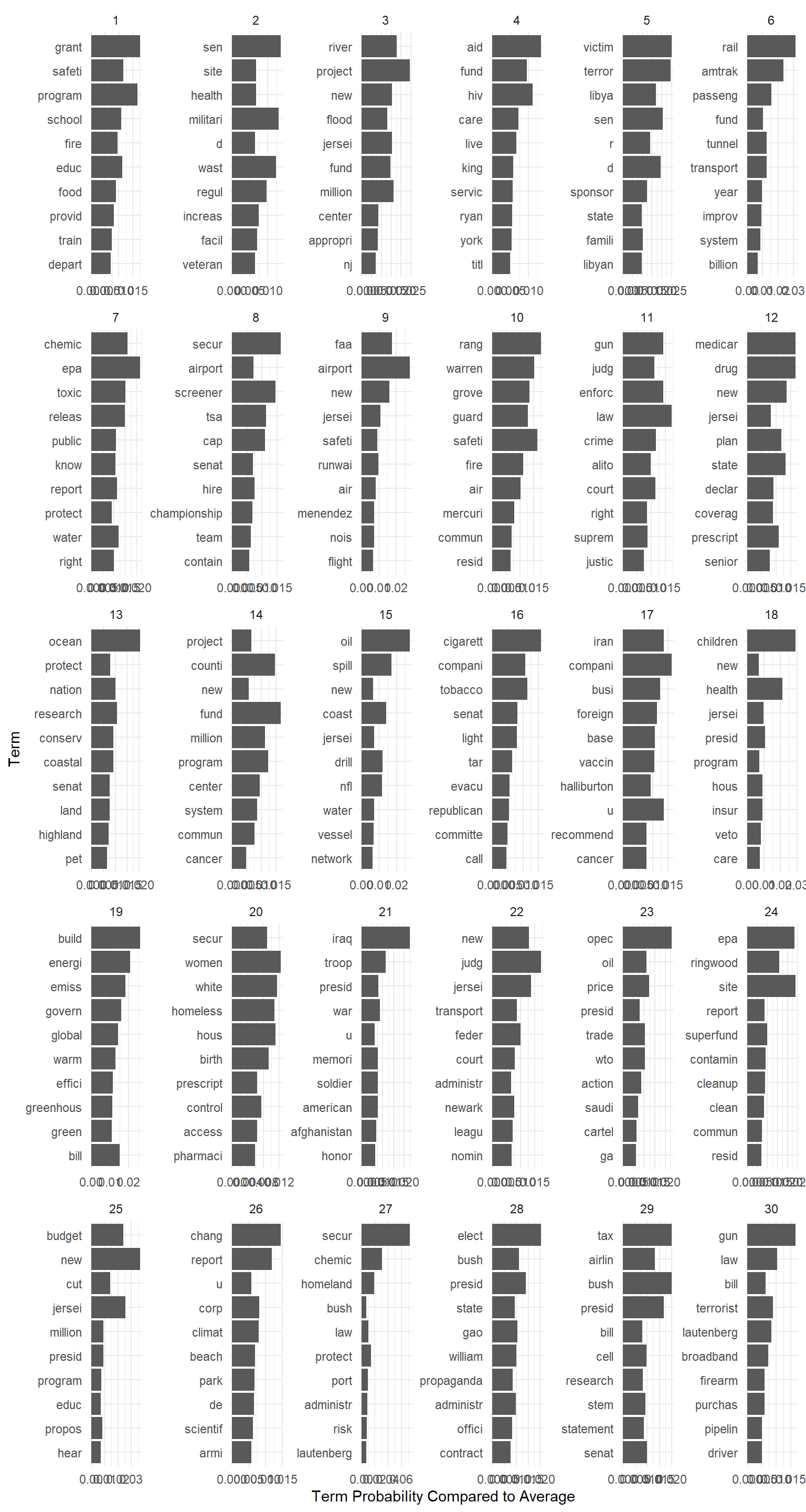
Topics 6 and 9 appear to involve words related to transportation infrastructure, while topics 2, 5, 8, 17, 21, 23, 27, and 30 appear to be about security, the miltary, and foreign affairs. Topics 3, 7, 10, 13, 15, 19, 24, and 26 are all related to the environment. This all seems consistent with Senator Lautenberg’s work as chairman of the Senate subcommittees on Homeland Security, Surface Transportation Security, and Superfund, Toxics, and Environmental Health – which should give us some confidence in the results. Topics 28 and 29 look like the “partisan taunting” category identified in the book.
Step 5: Interpret the Document-Level Probability Vectors
If these are roughly how we would categorize each topic…
topic_labels <- tribble(~topic, ~label,
1, 'Programs',
2, 'Military',
3, 'Environment',
4, 'Health',
5, 'Security',
6, 'Transportation',
7, 'Environment',
8, 'Security',
9, 'Transportation',
10, 'Environment',
11, 'Crime and Courts',
12, 'Health',
13, 'Environment',
14, 'Programs',
15, 'Environment',
16, 'Health',
17, 'Military',
18, 'Health',
19, 'Environment',
20, 'Health',
21, 'Military',
22, 'Crime and Courts',
23, 'Oil',
24, 'Environment',
25, 'New Jersey',
26, 'Environment',
27, 'Security',
28, 'Partisan Taunting',
29, 'Partisan Taunting',
30, 'Security')…then here’s what the breakdown in topics across the 558 press releases looks like.
lautenberg_documents <- tidy(lautenberg_lda, matrix = 'gamma')
lautenberg_documents |>
# join with topic labels
mutate(document = as.numeric(document)) |>
left_join(topic_labels, by = 'topic') |>
# get the most probable document labels
filter(gamma > 0.3) |>
arrange(document, -gamma) |>
head(20)# A tibble: 20 × 4
document topic gamma label
<dbl> <dbl> <dbl> <chr>
1 1 22 0.999 Crime and Courts
2 2 18 0.999 Health
3 3 23 0.999 Oil
4 4 7 0.976 Environment
5 5 11 0.693 Crime and Courts
6 5 29 0.302 Partisan Taunting
7 6 26 0.912 Environment
8 7 6 0.936 Transportation
9 8 11 0.897 Crime and Courts
10 9 16 0.991 Health
11 10 18 0.996 Health
12 11 13 0.520 Environment
13 11 17 0.382 Military
14 12 10 0.477 Environment
15 12 7 0.363 Environment
16 13 9 0.403 Transportation
17 13 6 0.318 Transportation
18 14 24 0.705 Environment
19 15 27 0.999 Security
20 16 21 0.998 Military Document 1 should be about Crime/Courts.
Senator Frank R Lautenberg Press Release of Senator Lautenberg Lautenberg Cites
Criminal Laws DeLay May Have Broken in Threat Against Federal Judges Friday
April 1 2005 WASHINGTON DC Responding to possible violations of criminal law
by House Majority Leader Tom DeLay when he directed threatening remarks toward
federal judges involved in the Terri Schiavo case Untied Stated Senator Frank R
Lautenberg today called on Mr DeLay to renounce his comments In a letter to Mr
DeLay Senator Lautenberg said the remarks could incite violence against judges
and noted that federal statutes provide for prison terms up to six years for
threatening members of the court Threats against specific Federal judges are
not only a serious crime but also beneath a Member of Congress In my view the
true measure of democracy is how it dispenses justice Your attempt to intimidate
judges in America not only threatens our courts but our fundamental democracy
as well wrote Lautenberg in his letter to Mr DeLay Majority Leader DeLay s
comments yesterday may violate a Federal criminal statute 18 U S C 115 a 1 B
That law states Whoever threatens to assault or murder a United States judge
with intent to retaliate against such judge on account of the performance of
official duties shall be punished by up to six years in prison A copy of the
entire letter is attached to this release April 1 2005 Tom DeLay Majority Leader
House of Representatives Washington DC 20515 Dear Majority Leader DeLay I was
stunned to read the threatening comments you made yesterday against Federal
judges and our nation s courts of law in general In reference to certain Federal
judges you stated The time will come for the men responsible for this to answer
for their behavior As you are surely aware the family of Federal Judge Joan H
Lefkow of Illinois was recently murdered in their home And at the state level
Judge Rowland W Barnes and others in his courtroom were gunned down in Georgia
Our nation s judges must be concerned for their safety and security when they
are asked to make difficult decisions every day That s why comments like those
you made are not only irresponsible but downright dangerous To make matters
worse is it appropriate to make threats directed at specific Federal and state
judges You should be aware that your comments yesterday may violate a Federal
criminal statute 18 U S C 115 a 1 B That law states Whoever threatens to
assault or murder a United States judge with intent to retaliate against such
judge on account of the performance of official duties shall be punished by up
to six years in prison Threats against specific Federal judges are not only a
serious crime but also beneath a Member of Congress In my view the true measure
of democracy is how it dispenses justice Your attempt to intimidate judges in
America not only threatens our courts but our fundamental democracy as well
Federal judges as well as state and local judges in our nation are honorable
public servants who make difficult decisions every day You owe them and all
Americans an apology for your reckless statements Sincerely Frank R Lautenberg
Questions or CommentsDocument 2 should be about Health.
print_text(df$text[2])Senator Frank R Lautenberg Press Release of Senator Lautenberg Sens Lautenberg
and Menendez Lead Defeat of Amendment Specifically Targeting NJ s Children
Health Coverage Bunning Amendment Would Cast Thousands of NJ Children Into The
Ranks of The Uninsured Contact Press Office 202 224 3224 Wednesday August 1 2007
WASHINGTON New Jersey Senators Frank R Lautenberg D NJ and Robert Menendez D NJ
led the effort that tonight resulted in the defeat of an amendment specifically
targeting childrens health insurance in New Jersey The Bunning amendment to
the Childrens Health Insurance Program CHIP reauthorization bill was tabled by
a 53 43 vote The amendment was a direct shot at New Jerseys FamilyCare program
which covers children from families that make up to 350 of the federal poverty
level working and low income families that dont qualify for Medicaid but cannot
afford health insurance in a high cost of living state like New Jersey Had
the amendment passed only children in New Jersey would have been immediately
affected Lautenberg and Menendez helped persuade colleagues to oppose the
amendment and spoke vehemently in opposition Today the U S Senate defeated an
attack on the health of New Jerseys children said Lautenberg We stood strong
against right wing efforts to take away the health insurance of 3 000 children
in New Jersey This vote means we can continue to provide quality affordable
health care to children in New Jersey and nationwide This was a rifle shot at
New Jersey and we worked hard to make our colleagues understand what it meant
for our states children and why it had to be deflected said Menendez Without
this level of coverage thousands of New Jersey children would have been dropped
into the ocean of the uninsured Throughout the debate on this bill we have
been repeatedly confronted with amendments attacking coverage for children and
families in New Jersey and we have repeatedly held our ground and rejected them
Todays action brings us one step closer to a major victory for working and low
income children and families in our state Among the amendments offered to this
point during Senate debate of CHIP three in particular have taken aim at New
Jerseys strong health coverage program and all three have been defeated Bunning
Amendment Motion to Table Passed 53 43 This amendment would have reduced the
reimbursement rate for CHIP covered children above 300 of poverty in all states
to the Medicaid matching rate including states that already cover these kids
under CHIP Only New Jersey has an eligibility level above 300 now in effect New
York has enacted legislation increasing its eligibility to 400 but has not yet
gotten approval from the Secretary of HHS for its state plan amendment to make
the change This amendment unfairly targeted a small percentage of CHIP covered
children in New Jersey This amendment would have pushed 3 000 New Jersey kids
off the CHIP program Gregg Amendment Failed 42 53 This amendment would have
pushed all parents covered under CHIP into Medicaid Over 80 000 parents would
have lost coverage in NJ Allard Amendment Failed 37 59 The amendment would
have disallowed states from using any type of income disregards to determine
eligibility in CHIP Under current law states are permitted to disregard types
of income or blocks of income and most states use this flexibility to disregard
wages child support payments and child care expenses to enable working families
to earn a living wage and still be eligible for CHIP This amendment would have
disrupted NJs ability to enroll children at a higher income level in CHIP It
would have prevented us from covering kids above 200 of the federal poverty
level and would have jeopardized coverage for over 30 000 New Jersey children
Questions or CommentsDocument 5 seems to be some combination of Crime/Courts and Partisan Taunting.
print_text(df$text[5])Senator Frank R Lautenberg Press Release of Senator Lautenberg Statement by
Senator Lautenberg on the Retirement of Justice Sandra Day O Connor Friday
July 1 2005 WASHINGTON D C United States Senator Frank R Lautenberg issued
the following statement today regarding the retirement of Justice Sandra
Day O Connor Justice O Connor has earned a place in history not only as the
first woman to serve on the Supreme Court but also as an independent thinker
who avoided extreme positions The American people want fair moderate judges
protecting our rights and I strongly urge President Bush to send us a nominee
who reflects mainstream legal views not partisan extremes Questions or CommentsNot bad! It’s a press release that is mostly honoring Sandra Day O’Connor, but the last sentence is a dig at President Bush.
Practice Problems
Fit an LDA to the Federalist Paper corpus (instead of focusing on stop words as in the authorship prediction task, I’d advice removing stop words and focusing on the substantive terms). What sorts of topics does the model produce? What value of \(k\) yields the most sensible set of topics?
Fit an LDA to the UN Security Council speeches about Afghanistan (Schoenfeld et al. 2018), available at
data/un-security-council/UNSC_Afghan_Spchs_Meta.RDataon the repository.
Further Reading
- Grimmer, Stewart, and Roberts (2021) Chapter 13
- Text Ming With
RChapter 6 - For a principled procedure for varying \(k\) to identify the best set of topics, see Wilkerson and Casas (2017) .