set.seed(42)
pop <- round(runif(1e5, min = 18, max = 100))
mean(pop)[1] 59.05816var(pop)[1] 563.7778Last week, we introduced probability theory from the perspective of sampling. We have some population of interest, and we imagine all the possible samples that we could draw from the population. With this sampling distribution in hand, we have a better sense of how far from the truth a sample estimate might be.
This week, we turn that question on its head. We are no longer an omniscient being who can sample ad infinitum from the population. Instead, we are a humble researcher with a single sample. What conclusions can we draw? How confident are we that our sample is not way out in the tails of the sampling distribution? That is a task for statistical inference.
By the end of this week, you will be able to:
Conduct null hypothesis tests
Communicate uncertainty around your estimates from samples using confidence intervals, p-values, and standard errors
In this problem set, you are going to prove to yourself that a 95% confidence interval contains the truth about 95% of the time when your sample is randomly drawn from the population.
To begin, load the cards.csv dataset we worked with in the last problem. Submit your responses to the following problems as a knitted R script or Quarto document.
truth, equal to the average number of the cards in the deck.truth?for() loop to repeat that process 10,000 times, each time recording 1 if your confidence interval contains the truth and 0 otherwise. What fraction of your confidence intervals contain the truth?truth which contains this difference in means for the entire deck of cards.truth?for() loop to repeat that process 10,000 times, each time recording 1 if your confidence interval contains the truth and 0 otherwise. What fraction of your confidence intervals contain the truth?biden column contains the share of voters who said they planned to vote for Joe Biden. For each poll, construct a 95% confidence interval for the sample mean based on the assumption of Bernoulli random sampling. What fraction of the polls contain Biden’s true vote share in Georgia (49.47%)? What about just the polls conducted within two weeks of the election date? Briefly explain what you think this result says about the most important sources of uncertainty in election polling.Every statistic has a sampling distribution. When we conduct a hypothesis test, we compare our observed statistic to its sampling distribution to assess whether that statistic is something we would have expected due to chance alone. Every single null hypothesis test you will ever perform proceeds in three steps:
Compute the test statistic
Generate the sampling distribution assuming a null hypothesis
Compare the test statistic with its sampling distribution. This comparison will take one of two forms:
A p-value (if the null hypothesis were true, how surprising would my test statistic be?)
A confidence interval (what is the set of null hypotheses for which my test statistic would not be surprising?)
A statistic can be anything you compute from data! So far we’ve computed statistics like:
The sample mean1
The difference in means
Variance
Linear model coefficients
A word on notation: statisticians denote population-level parameters with Greek letters.2 So the population mean is typically \(\mu\), the population standard deviation is \(\sigma\), the true average treatment effect is \(\tau\), and the true linear model slope coefficient is \(\beta\). Of course, you can write whatever Greek letters you like. These are just conventions.
Sample statistics get plain old English letters, like \(b\) for an estimated slope or \(s\) for a the standard deviation of a sample. Alternatively, they might get little hats on top of Greek letters, like \(\hat{\beta}\), to show that they are estimates of the population-level parameter we care about.
As a running example, suppose we have a random sample of 100 people from a population of interest. We want to test whether the average age of the population is equal to 60.
set.seed(42)
pop <- round(runif(1e5, min = 18, max = 100))
mean(pop)[1] 59.05816var(pop)[1] 563.7778Now let’s randomly sample 100 people from the population.
samp <- sample(pop, size = 100)
mean(samp)[1] 62.55Do we have enough evidence from this sample to reject the hypothesis?
As we established last week, the sampling distribution of the sample mean should be approximately normally distributed with mean equal to \(\mu\) and variance equal to \(\frac{\sigma}{n}\). But last week, we knew the values of \(\mu\) and \(\sigma\). This week, we only have this one sample of 100 people. So our trick will be to estimate the standard error of the sampling distribution based on the sample variance.
se <- sqrt(var(samp)/length(samp))If the null hypothesis were true, then the sampling distribution of the sample mean would be a normal distribution with standard deviation equal to \(\sqrt{\frac{\sigma}{n}}\) centered on the null hypothesis.
x <- seq(50, 70, 0.1)
y <- dnorm(x, mean = 60, sd = se)
plot(x,y,type = 'l', lty='dashed')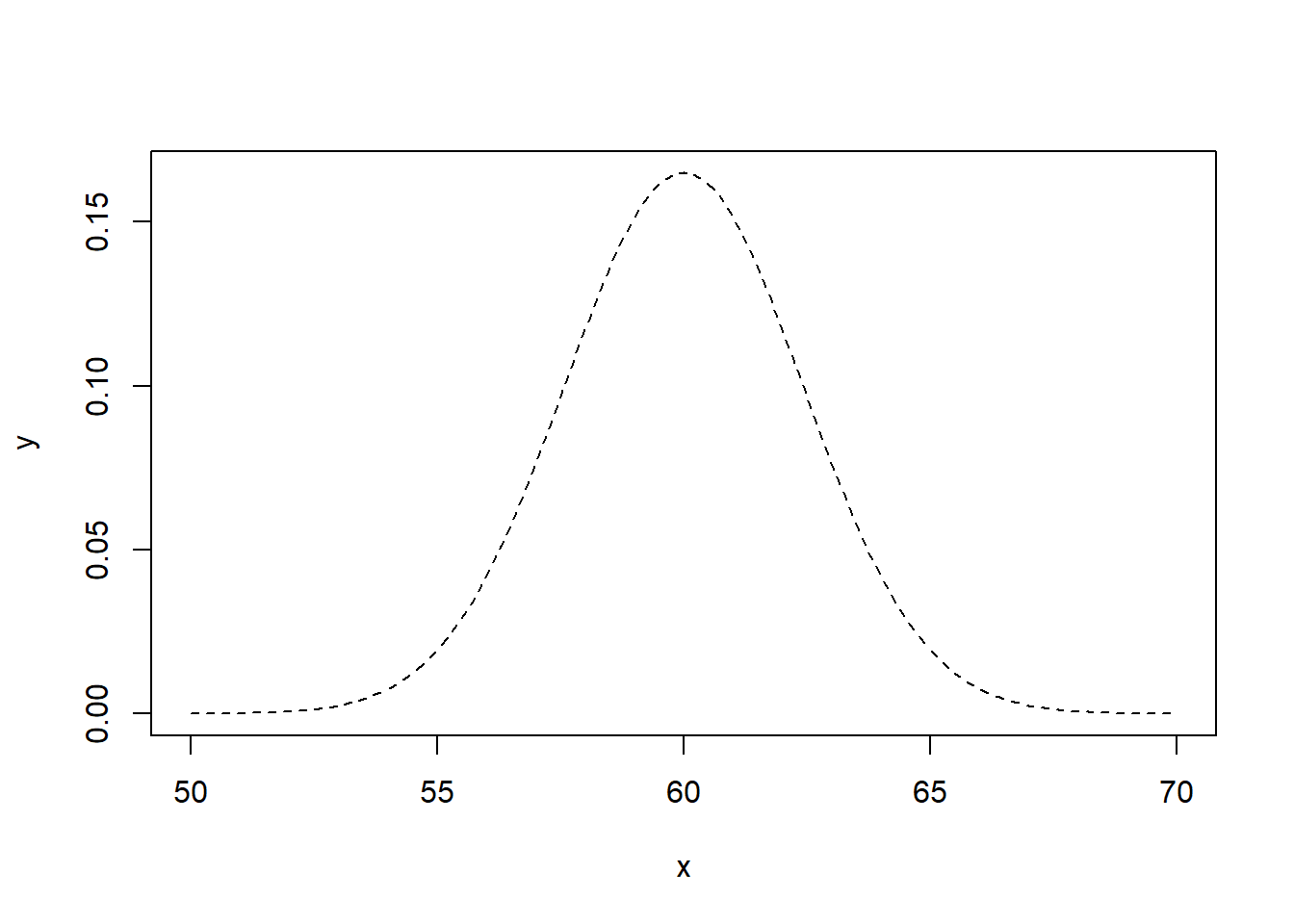
The test statistic falls here:
plot(x,y,type = 'l', lty='dashed')
abline(v = mean(samp), col = 'red')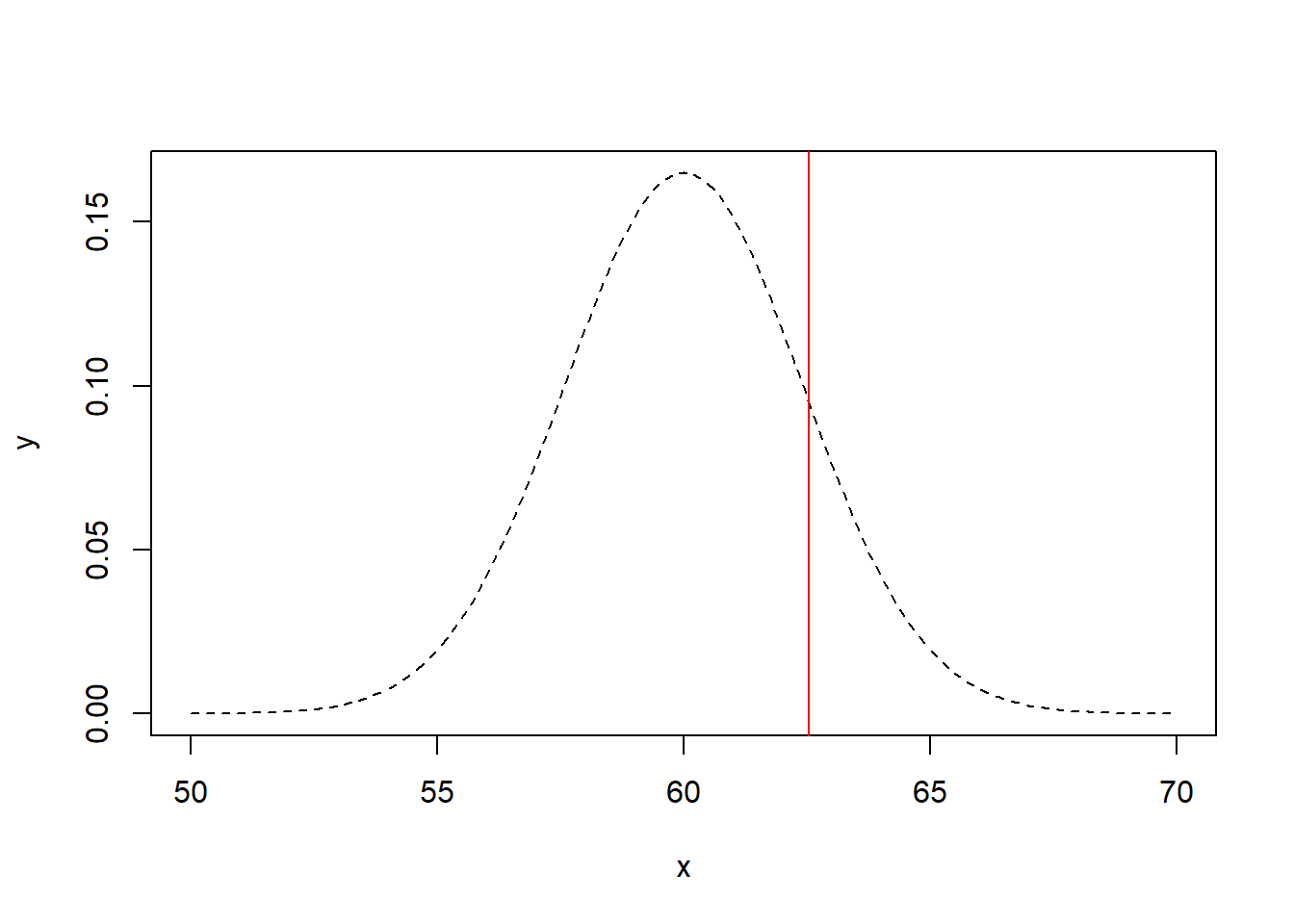
What’s the probability of observing a test statistic that far away from 60 if the null hypothesis were true (the p-value)?
Well, to answer that question we need to take a brief digression into integral calculus.
Hey welcome back from the digression into integral calculus. It may interest you to know that what we just called the “area function” \(F(x)\) is, when applied to a probability distribution function, called the cumulative distribution function. It tells you the probability that the random variable is less than or equal to \(x\). And conveniently for us, R has a bunch of cumulative distribution functions built in. For a normal distribution, you want thepnorm() function.
# the probability that a value drawn from a standard normal distribution will be 2 or less
pnorm(2)[1] 0.9772499# the probability that a value drawn from N(2,1) will be 2 or less
pnorm(2, mean = 2, sd = 1)[1] 0.5To bring it back to our motivating example, we’d like to know the probability that a value randomly drawn from \(N(60, \sqrt{\frac{s}{n}})\) will be as far away from 60 as our observed data. That will be the sum of two areas:
pnorm(mean(samp), mean = 60, sd = se, lower.tail = FALSE) +
pnorm(60 - (mean(samp) - 60), mean = 60, sd = se, lower.tail = TRUE)[1] 0.2918633There is roughly a 2/3 chance that we would observe a test statistic at least that far away from 60, even if the null hypothesis were true! We do not have enough evidence to reject the null hypothesis.
What is the set of null hypotheses that we would fail to reject? The set of values, in other words, that are consistent with the observed evidence (a confidence interval)?
mean(samp) - 1.96 * se[1] 57.80826mean(samp) + 1.96 * se[1] 67.29174A confidence interval, constructed this way, would contain the true value 95% of the time if we repeatedly drew random samples from the population.
The reason why statisticians like means as a measure of central tendency is because of Central Limit Theorem! The sampling distribution of the mean is normally distributed; no such guarantee for other statistics like medians or modes.↩︎
Because mathematicians associate timeless truth and beauty with the ancient Greeks?↩︎